Изучение сложной структуры гена шло параллельно с развитием представлений о функции гена, т. е. с изучением конкретной роли генов в формировании тех или иных признаков организма.
Значительный прогресс в понимании функции гена достигнут благодаря исследованиям Дж. Бидла и Е. Татума (1941), заложивших основы биохимической генетики. Эти авторы, исследуя биохимические мутации у Neurospora crassa, показали, что большинство генов контролирует синтез специфических белков — ферментов: мутации генов выражаются прежде всего в изменении или потере фиктивности соответствующих ферментов. Бидл и Татум выдвинули положение «один ген — один фермент». В настоящее время это Положение следует понимать в том смысле, что для каждого белка клетки существует ген, контролирующий его структуру и активность.
В дальнейшем положение «один ген — один фермент» было развито Ф. Криком в виде «гипотезы последовательности», которая уводится к тому, что последовательность элементов гена (чередование нуклеотидов ДНК) детерминирует последовательность элементов белковой молекулы (чередование аминокислот в полипептидной цепи). В пользу этого предположения говорит тот факт, что мутации, представляющие собой замены отдельных нуклеотидных пар ДНК гена, выражаются в виде замен отдельных аминокислот в соответствующей белковой молекуле. Так, в случае тяжелого наследованного заболевания крови у человека — серповидно-клеточной анемии — происходит изменение свойств гемоглобина. При этом молекуле гемоглобина, состоящей примерно из 500 аминокислотных остатков, происходит замена лишь одного аминокислотного остатка: глутаминовая кислота заменяется на валин.
Справедливость «гипотезы последовательности» была доказана, в частности, работами Ч. Яновского с сотрудниками. Авторы исследовали тонкую структуру локуса, контролирующего фермент триптофансинтетазу у Escherichia coli. Они проводили картирование мутаций в пределах одного гена и параллельно изучали аминокислотные замены в белке. Оказалось, что девять мутационных участков на линейной карте гена расположены в той же последовательности, что и соответствующие девять аминокислотных остатков, которые заменялись в полипептиде при мутационных изменениях. Так было доказано существование параллельного соответствия (колинеарности) гена и контролируемого им белка.
Итак, было-установлено, что ген контролирует последовательность аминокислот в белке. Это возможно благодаря существованию нуклеотидного кода ДНК. Вся клетка работает подобно высокоспециализированной машине перевода с языка нуклеотидов на язык аминокислот. В настоящее время благодаря усилиям генетиков и биохимиков мы узнали основные черты генетического кода и белков. Каждый аминокислоте соответствуют три пары оснований ДНК, т. е. код является триплетным. Это было доказано в экспериментах Ф. Крика с сотрудниками, использовавшими мутации rII (ген В) фага Т4.
Рассуждения Крика можно представить себе следующим образом. Обозначим сочетание из трех пар нуклеотидов как abc. Далее допустим, что такие триплеты повторяются последовательно в отрезке молекулы ДНК: abc abc abc abc.
При этом между каждыми двумя последовательными триплетами нет никаких дополнительных соединений, и они не перекрывают друг друга, т. е. один и тот же нуклеотид не может входить одно временно в состав двух триплетов.
Важным условием действия таких триплетов является то, что каждый триплет кодирует только одну аминокислоту в полипептидной цепочке.
Представим себе, что произошла мутация, например вставка лишнего, тогда весь последующий порядок «считывания» триплетов нарушится, так как код считывается слева направо тройками:
abcaa bcabcabcab…
После этого где-то недалеко вправо от первоначальной мутации возникла новая мутация, заключающаяся в выпадении одного какого-нибудь основания.
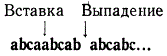
Мы видим, что в данном случае нарушение первоначального порядка считывания триплетов имеет место только на участке между двумя мутациями (указано стрелками), на всем остальном протяжении сохраняется прежний порядок считывания. Если данная часть гена, в которую входит несколько триплетов, не выполняет какой-нибудь ответственной функции, то можно представить, что нарушение считывания кода на каком-то небольшом участке не скажется заметным образом на конечном результате. Особи, несущие два таких изменения, будут иметь фенотип, приближающийся к дикому типу. Вторая мутация (выпадение) сыграла роль подавителя, супрессора, по отношению к первой мутации.
Но если бы не было выпадения, а произошла бы только вставка, то считывание также оказалось бы нарушенным. В данном случае нет принципиальной разницы между первой мутацией — вставкой и второй мутаций — выпадением, играющей роль подавителя (восстановителя нормального считывания триплетов).
Вставка и выпадение одного нуклеотида были условно обозначены знаками плюс (+) и минус (—). В опытах Крика с сотрудниками было получено большое количество мутаций того и другого знака. При комбинировании их попарно (+ и —) в одной нити ДНК они давали, как правило, нормальный или псевдонормальный фенотип.
Если код действительно является триплетным, то комбинации + + двух вставок оснований или — —, т. е. двух выпадений, должны всегда давать мутантный фенотип, тогда как комбинации + + + или — — — при достаточно близком расположении мутаций друг около друга должны давать фенотип, приближающийся к норме, поскольку в этом случае восстанавливается нормальный порядок считывания кода. Эти предположения получили экспериментальное подтверждение при скрещивании определенных мутантов фага Т4. Результаты скрещивания соответствовали заранее предсказанным, что и явилось проверкой гипотезы кодирования наследственности и молекулярной основы мутаций.
Следующий этап в расшифровке генетического кода заключается в выяснении состава триплетов и последовательности оснований в триплетах. Для того чтобы рассмотреть конкретную структуру триплетов, необходимо обратиться к молекулярным основам функционирования генов.